What You’ll Learn in 1 Year as a Data Scientist
Around 1 year ago, after working on several academic research projects and many data science courses, I have finally landed an applied data science position at a rapidly growing e-commerce firm. I will try to share the things I’ve learned on the job that are not well known beforehand by at-home data science enthusiasts.
1. Working on a Remote Server
Most people start their data science journey on their computers. However, in an actual data science project the required computing power and memory is much more than a laptop can provide. Thus data scientists use their computers to access a remote server, usually using an SSH (Secure Shell) connection. SSH lets a user to access another computer securely using a private key (ssh key). Once a connection is established, remote server can be used as if it is the shell of your computer. Speaking of shell, knowing the basic shell commands help with the transition to work on a remote server.
2. SQL Is the King
Data science and machine learning is done on Python, Julia and R right? Wrong, it is done on SQL! Every data science project starts with the data and most of the time the data to be used for the problem will not be readily available, it should be created using the parts of data in several tables of a database.
SQL is the de facto standard database language that is used for joining, aggregating and selecting the parts of the needed data fast. Every data related position needs to be comfortable at using SQL since it is used intensively every day. Most people neglect on improving their SQL knowledge if not completely disregard learning it. It is natural, most enthusiasts do not have an access to a data base server and their data sets are already built by someone else. In reality, 90% of a data scientists time is spent on preparing and cleaning the training data. I know it’s kind of a bummer but if there is no data there is no data science.
It should be noted that SQL has many dialects however they are similar to each other and dissimilarities can be easily adapted. Just choose one dialect and start learning it!
3. Features Are More Important Than the Model
Linear models are usually seen as simle and not adequate for machine learning problems. I mean how much can you go with linearly adding your features and getting a result right? Actually, you can go a long way.
More sophisticated models such as random forest, xgboost, SVM, DNNs etc. find non-linear boundaries in the feature space (the space your explanatory variables reside). They do it by either dividing the feature space to smaller parts or mapping your features to a higher dimensional feature space and then drawing linear lines in this new space. In the end (with great simplification) they can all be thought as fitting a straight line through newly generated data points. Since the models do not know the intrinsic meaning of the features, they try to create this new features based on some kernel or by optimizing the pseudolikelihood function.

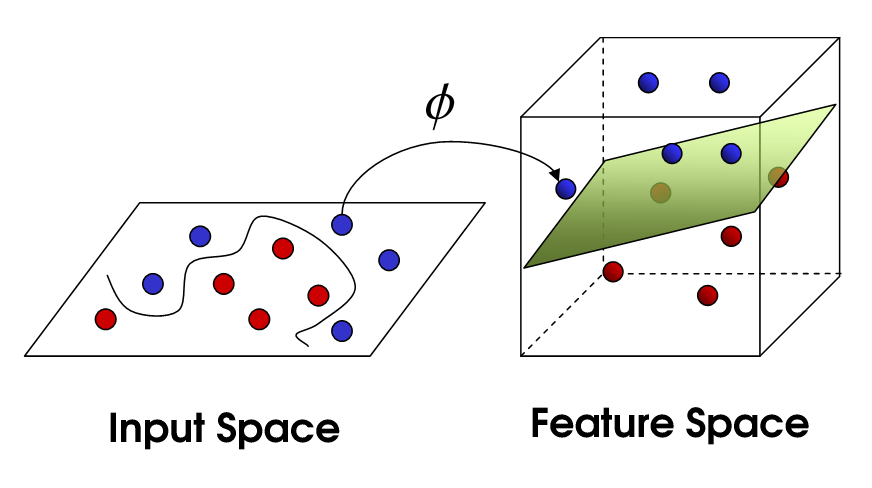
That seems complicated right? That’s why they are called gray/black box models. On the other hand, someone that knows the real meaning of the features can generate new meaningful fetures from the data. This feature generation, transformation, preprocessing and selection step is called feature engineering. Basic feature engineering approaches include taking the mean-standard deviation of the features, discretizing the continuous variables into bins, adding lagged/difference features and so on.
After proper feature engineering any model can achieve great results. Linear models are prefered because of their interpretability. You can see the significance, and coefficients of the generated features and make comments on the validity of the model. If a coefficient that should be logically positive comes out to be negative than there is probably something wrong with the model, the data or the made assumptions. Why is it so important? Because there is a basic rule, garbage in garbage out.
4. Difference Between Experimentation and Production
Most of the data science is done on Jupyter Notebooks due to its ease of use on experimentation and visualization. It is easy to quickly try something new, train a new model or see the result of some expression on notebooks, just open a new cell and have your way.
However the reign of jupyter notebook ends and reign of python files start when the model is ready to hit the production. Production (prod for short) is where your algorithms run on real life. The end user (internal or external) is affected by the code on the production thus production level code should be fast, clean, verbose, fault tolerant and easy to debug. Now what I mean by these?
The speed of your code is not so important if you are just experimenting and will run the code once or twice. However in the production your code will probably run multiple times every day and its results will affect other moving parts of the production ecosystem. Thus the duration of execution becomes important.
Let’s face it, some (if not all) of your notebooks are unordered, messy, has unused imports and has cells that are not actually needed anymore, right? It is all fine, you were just experimenting on your ideas. Now it is time to clean up your code so someone other than yourself can actually follow through the steps of your code. Your code becomes clean enough if anyone in your team can easily look at your code and understand the purpose of every line with ease. This is why you should give meaningful names to your variables and functions, don’t ninja-code it!
You should log the important steps of your code’s executions to the shell screen as well as to a log file. Console logging helps in visually seeing the steps that your code takes when you run it on the shell, keeping yoıu informed on the execution. Log files on the other hand help in identifying the possible problems encountered while running the code. A good log file should include the start and end time, summary of results, encountered exceptions and problems of each excution.
It’s a stressful event when a production code starts to fail for any reason and users start to see weird results. A good production code should be able to handle the possible exceptions and do required assertions beforehand and should alert the team if there is an unexpected/unresolvable problem. Depending on the situtation a failed code could be programmed to give results of the previous run, not give any output at all or provide predefined results. Time spent on comfortably writing fault tolerant code is usually better than stress coding during a problem.
Even if the code is fault tolerant there may be a bug inside the code that generates unintended results. In this case the code should be debugged, usually using a debugging tool, to find the reason. Clean coding makes debugging easier however is not enough. A coder should use functions instead of repeating the code, give a single purpose to each function and avoid using impure functions. This practices makes it easy to locate the source of the bug in the code.
For writing a production level code I recommend using a text editor such as VS Code rather than using jupyter notebook. Software development tools make developing easier and faster. If you still want to work with jupyter notebook there is a tool called nbconvert that creates python files from jupyter notebooks.
5. MVP
Tech world is competitive and fast changing. In most of the time there is no time to wait for a perfect product that achieves state-of-the-art performance. Instead of targeting for the perfect product tech companies start on a project and quickly build an MVP (minimum viable product) and iterate over that. An MVP is required to satisfy the most basic needs of the project, nothing fancy and nothing more.
For a prefectionist or a detail-oriented person (i.e. the majority of data science enthusiasts) it is often hard to work on an MVP. Most data scientists strive for carefully analzing the data, trying out many different features and models and coming up with the best possible model. Data science, as a field is inherently research oriented, however I didn’t specify applied data science for nothing.
This philosophy bothered me when I’ve first started but don’t wory, it is actually better this way. The most important asset is time. The path a project will take cannot be known beforehand, thus the time invested in the project is not guaranteed to be valuable. The project you have been working on can be put on hold or canceled completely based on the user feedbacks and A/B tests. The risk is minimized by building an MVP rather than a full-blown project. Even if the project is guaranteed to stay, most of the time enough data will not be available or possible future complications are not known. Building a simple model and iterating over that with the newly generated data and acquired know-how gives faster and more robust results.
6. Agile Development
Another concept in Tech world that comes with working in a team is Agile development. Agile is a development philosophy where project are divided into bite sized tasks and team members fetch new tasks from the backlog when they are available. Each task is given an estimated score by the team during sprint planning and team takes a total score of tasks for the sprint. It is actually easier said than done. Agile is developed for software engineering where taks durations are estimated more easily, paths and practices are well defined. Data science tasks on the other hand require trial and error and tasks durations are far harder to estimate due to high variance. It is kind of ironic that data scientist make accurate predictions for other business problems but cannot do the same for their tasks.
7. A/B Tests
You have trained and tuned a new model, tuned its hyperparameters and it gave terrific results in every test metric, beating the previous model by far. You need to deploy it into production immediately right? Unfortunately, no.
The heart of agile and data science is A/B tests. Your model may beat the previous model in testing and simulations however may fail in the real life. That is why it’s called a simulation, it is not actual reality. Training data is just a subset of past reality that is highly processed in the model making. Times can change, mistakes can be made and models cannot explain all the variation in data. A model is replaced with the previous one only if it can create a significant uplift in the A/B testing period.
8. Communicating With People From Various Disciplines
Being a data scientist is actually quite different from being a software developer or a scientist. Usually data scientists work closely with both business and technical people thus they are required to know both the business side and the technical side.
Business people are usually the internal customers of data scientists and business people do not care about the sophistication of your model or elegancy of your code, they care about the causes and effects. This is where linear and tree based models play a great role. White box models are easy to explain, intuitive and interpretable. Business people, especially in the beginning, will want to know why a decision was made by ML model until they trust that it works. Since models are built to serve the business needs they should be tailored for the needs of business people.
In the development and production of the models data scientists work closely with developers. Developers usually collect and feed the data pipeline and also use the results of your algorithms on the production. Technology — data science integration can be done in several ways. Developers may take the code of data scientists and turn them into production level code (making the 4th point somehow obsolete), provide an API for data scientists to feed their results or call the API of the model created by data scientists. Each way has its pros and cons and may be iterated over the life cycle.
Data scientist are need to be able to understand the needs of the business and limitations of the developers. They should communicate both business and data science related requirements to developers and abilities and limitations of the technical side to business people.
This post was originally written by Kaan Aytekin.