Pandas Makes Python Better

Something I’ve wanted to talk about for a long time is the strength that Pandas brings to Python. Pandas is an essential package for Data Science in Python because it’s versatile and really good at handling data. One component I really like about Pandas is its wonderful IPython and Numpy integration. This is to say, Pandas is made to be directly intertwined with Numpy just as peanut butter is to be with jelly. It’s no wonder that both of those combinations are sold together in one full, package.

Smucker’s Goober jokes aside, Pandas geniunely makes Python a more viable language for Data Science just by being built in it. This isn’t to say that Python doesn’t have a multitude of wonderful packages that emulate this exact effect, because Python has an uncountable number of packages for machine-learning and data processing. Pandas makes things that are relatively difficult, or more of a pain in other languages, incredibly easy in Python.
IPython
The biggest thing that backs Pandas is — well, Pandas itself. The package was from square one designed to incorporate staples of Data Science like IPython Notebooks and Numpy. The way that it’s all pieced together makes a lot of sense, but rather than just telling you that, I’ll show you what it’s like to use packages from another language, that being my favorite:
Julia
The package that we’ll use in order to create data-frames, funny enough, is DataFrames.jl. Of course, we’re going to be working with comma separated values files (CSV files) for now. So step one is to read in our data… But how do we do that? In the change-logs there is a brief mention of a method called read_table, but for the most part this certainly seems to be deprecated.

Well, that’s the trick, in order to read in our DataFrames with DataFrames.jl, we actually have to get another package called CSV.jl. After adding that package, we can open our CSV file with the read() method:
using CSV
df = CSV.read("Fizzbuzz")
Awesome, now we’ve read in our data, but we get an interesting message at the top…
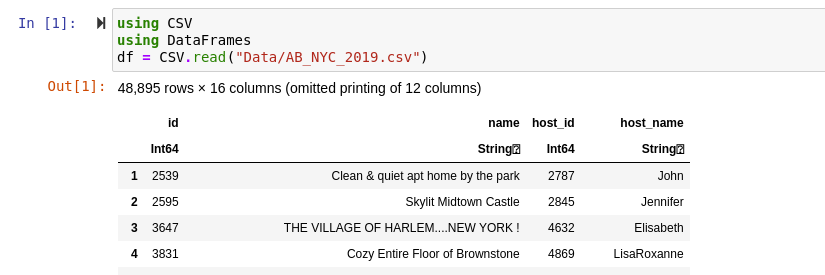
“ omitted printing of 12 columns”
Well, that’s nice and all, but why? For some odd reason, they chose to render the data-frames outside of an Iframe with columns omitted depending on a particular length of columns. So how do we get all the columns to show? It’s pretty easy to show all of the columns, just add a bool type parameter to the show method, like so:

Hold on, what is that? That’s right, it goes to a text-based data-frame with the columns printed
on top of each-other.
The good news is, the old showall!() method that we used to have to use is now deprecated, meaning that we don’t have to show ALL ROWS when we show ALL COLUMNS. This is quite possibly the reason I started using dictionaries instead a while back…
Okay, well now we’re aware of how hard this is in Julia, but what about Pandas? Well, you wouldn’t think it would be so simple, but the only package you need is Pandas, the only method you need is read_csv, and last, but not least, you can use the function df.head() to print out a head length of your choice, and df.tail() to print out a tail length of your choice. Not to mention, it looks like this:

Trust me on this, R’s data frames are not as good as Pandas, either, and for the most part people using R and Julia tend to PyCall Pandas, rather than using their respective language’s data-frame packages.
Numpy

Numpy is another part of the three musketeers of Data Science packages for Python. The Numpy integration allows for use of all of Numpy’s linear algebra inside of data-frames. Additionally, parts of Numpy make data-processing a lot easier. Just watch me destroy over a thousand null values in the blink of an eye!

It’s important to remember that vanilla Python and linear algebra actually don’t get along as well as you would think, given that it’s a programming language. I presume this is simply because Python was made to be higher level than “ linear algebra” and was of course not expected to become the statistical language that many companies are now knee-deep in. Of course, my df.dropna() example is pretty light, but it is guaranteed that at some point the close integration with Numpy is going to make your life a lot easier than it would have been otherwise!
Pandas Itself
Besides Pandas wonderful integration and methodology around other Python packages, Pandas has a host of benefits that all of the wonderful open-source work they have done has provided. Every twist, every turn, indexing, concatenating, melting, pivoting, even cross-tabulations can all be done in one line with Pandas. These are tasks that genuinely could provide a full hour’s work in other packages, but with Pandas — it’s easy and instant.
Using Pandas is made even easier with simple tools like the replace() function, which can be used to replace NaNs, or just weird data. Pandas makes a lot of work a little bit of work, and that’s what makes it so popular and impressive. But there are a few more enormous benefits to Pandas.
String Accessors
Yes, the legend is true:
data-frames are glorified dictionaries.
But not all dictionaries are created equal. Firstly, out of the languages that I know, Pandas’ conditional masking is by far the best.
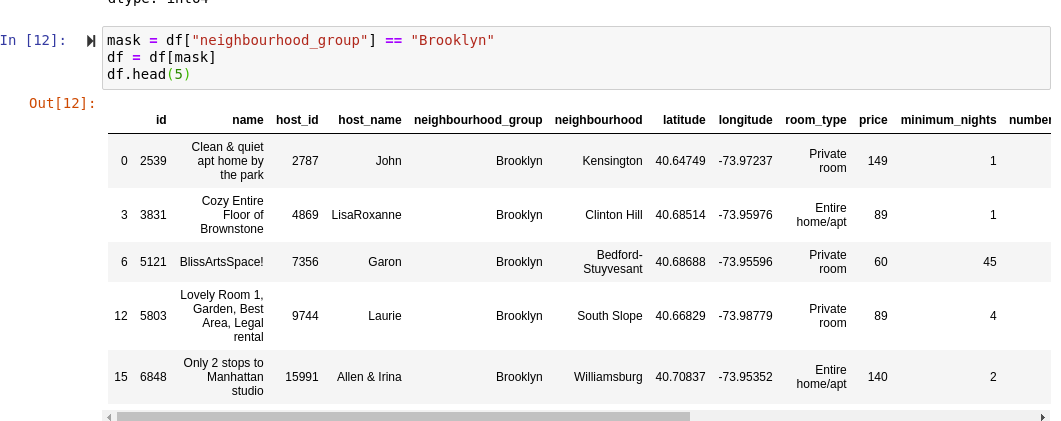
In one easy step, the data is completely filtered and ready to go, all contained inside of Pandas without actually running any additional methods — because after all, it’s just a dictionary.
Julia has dictionaries as well, and their DataFrames.jl package is, of course, the exact same system, but in my opinion, it falls flat on its face when it tries to stand with Pandas in this case. Firstly, in order to use a bool type mask we use the filter!() method. No problem with that, it’s a little less elegant, but regardless it works perfectly fine. But in Julia dictionaries in general, there is a pretty significant issue which I’m surprised hasn’t been touched on much.
Julia’s dictionary naming scheme uses symbols rather than strings. This is very problematic because of that evil thing that lingers at the base of all of our keyboards,
The Spacebar.

As you can see, the typical string naming-scheme doesn’t work in Julia. Instead, Julia uses symbols which are created by putting a colon before a variable name. So let’s try it with a symbol instead:
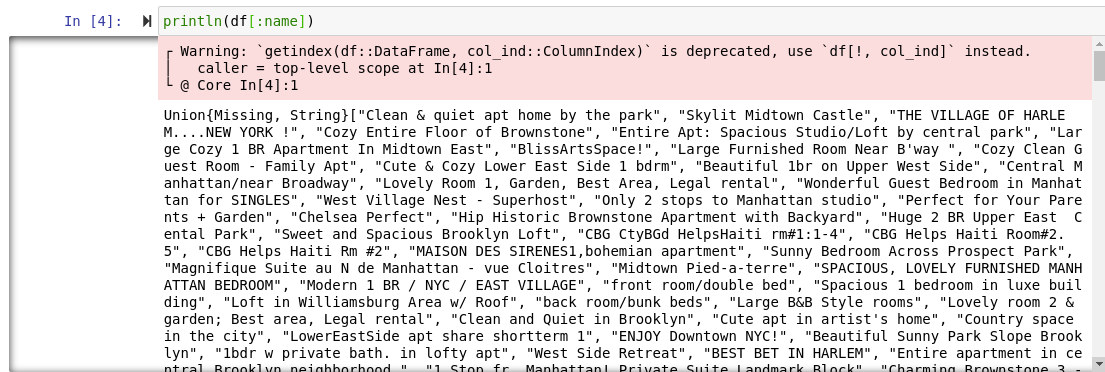
Okay so that works, but how would we do this with a space? Well, that’s the big issue, there is no way to access the column if it has a space in the name, no way at all. Of course, most data-frames won’t have spaces in the column names, as it’s considered more proper to use _ rather than a space, but what if one does? The only significant solution in Julia would be to open up the CSV file and change the column name in there, and that’s a big problem.
Conclusion
I love Pandas.
Pandas is such a great package, and makes Data Science a complete and total breeze for the most part. I certainly hope that DataFrames.jl can emulate what Pandas has created for the Python Data Science community. What is truly great about Pandas is how the entire tech stack around it flows seamlessly with it.
The Python universe is certainly a pretty one.