After all what’s new in Data Science?
Originally published on Towards Data Science by Marcos Silva.
What is the scope of work and the role of the data scientist.
We are increasingly hearing about this “new” craft called Data Science and its professional, the Data Scientist. But in the end, what does a Data Scientist do? Will the individual really work in a white coat and goggles? To analyze this, we may first understand that it is science, what has changed in the last decade to legitimize this new concept and how this new area and profession compare with the rest of the new and old functions?


First let’s examine what science is.
What does a field of study need to have to be considered science? After all, what is science? Many different authors have given unlike definitions for this concept. For our most practical purposes, let’s consider the concept of science by Karl Popper (1902–94), a science philosopher. For him, science is anything that can be falsified and/or plausible of falsifiability, otherwise it would belong to the realm of beliefs and opinions. It sounds simple, but it solves many of great philosophers’ deadlocks from the past, like Hume and Kant.


Let’s go for examples: Before Magellan in the 15th century, saying the earth was flat has to do with science, once we could test this hypothesis. Newton’s law of universal gravitation is also part of science because we can test and try to prove it is false. Now, if a moral decision is better or worse, it is not part of the scope of science since we cannot test it, or if I believe in one religion or another, it is not part of the scope of science either, again because it is not possible to test it.
If the scope of science is attempting to falsify hypotheses, and as models pass the tests of falsifiability over time, we believe in theories as scientific facts, as Newton’s laws survived for two centuries of try-outs, until even better upcoming theories and models, as Einstein did in 1915 with gravity, and still science keeps going. Therefore, along with this definition, science does not prove that a model is true, but not false.
And what does this have to do with Data Science?
Well, if science is a skeptical attitude against facts, creating models that try to explain reality, or testing hypotheses with a rigid methodology for other people possibly try to reproduce and falsify, Data Science is basically doing it now with data, right? Yes! But this is called Statistics.
What is the difference between Statistics and Data Science.
Obviously, they are quite related areas, which often relay on same sources. But what are its differences? By the way, is there any difference? For many people, no. Let’s go a little deeper. Statistics would be to Data Science as mathematics is to engineer, that is, it creates the theoretical framework for Data Science to solve real world problems, just like engineering does. The Data Scientist needs more than just pen and paper to solve these real world problems, using lots of programming techniques to deal with an ever-increasing amount of data, and then differences begin.

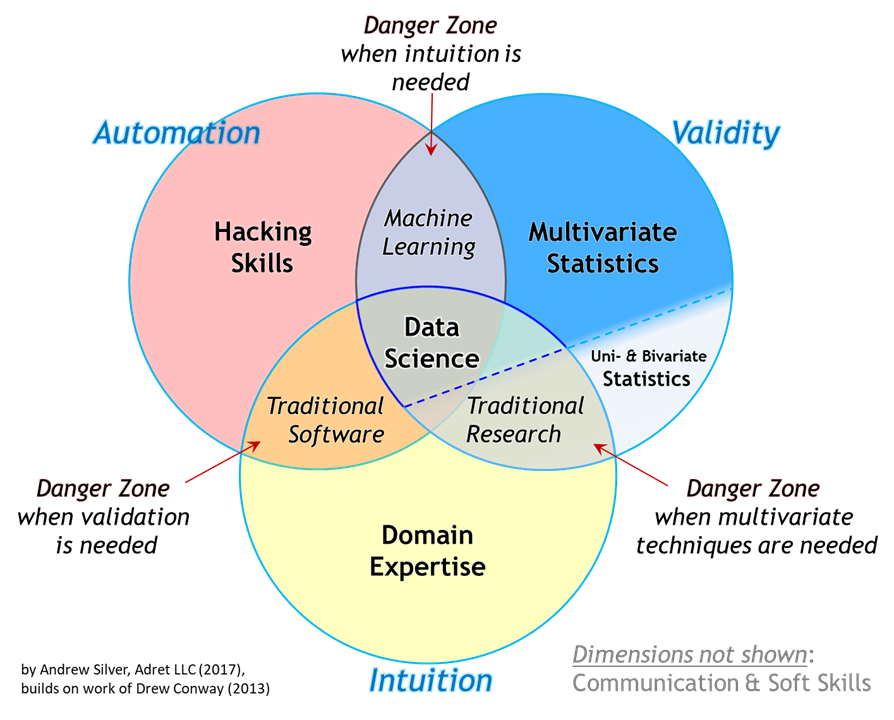
Data Science is a multidisciplinary area where one of its disciplines (perhaps the most important) being statistics, which all credits of data “science” comes from in a way that, without statistics, it would be just scientific content application, as same old engineering. In any case, there is no consensus yet as to where one area begins and the other ends so that there is a lot of overlap between both, thus this creates several initiatives to bring these fields together. 50 year of Data Science, MIT.
What has changed in recent years to increase Data Science popularity?
Much has changed in recent years that there has co-responsibility for the Data Science boom. Again, there is no obvious way to explain its rapid rise. Statistical theories are quite old — regression for example is from the late nineteenth century. Neural networks began to be explored in the 1950’s. So, what happened around 2010 that started this quick upside? The gaming industry!

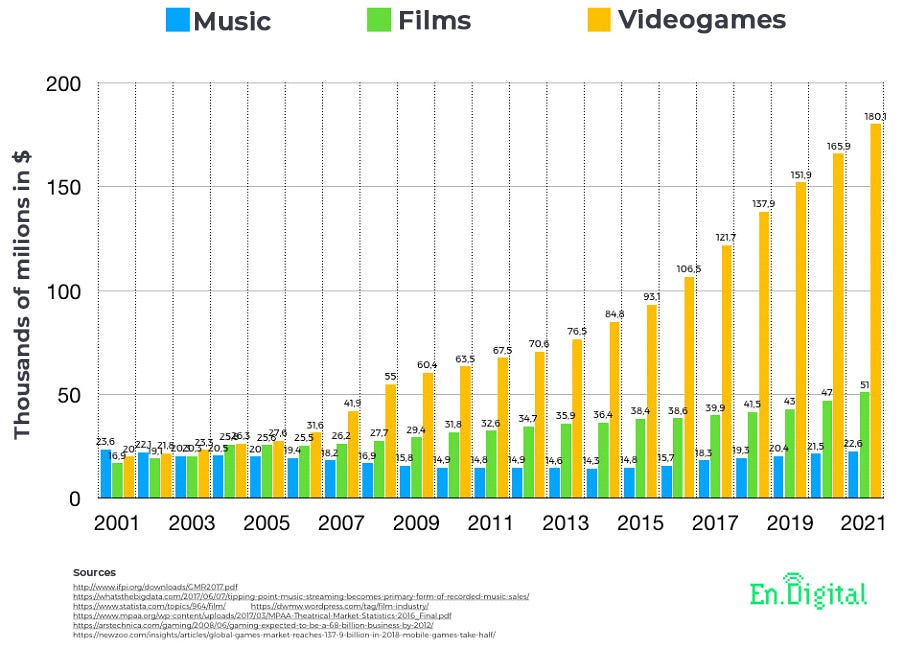
Hardware research investing is extremely expensive, and even though Data Science and Machine Learning are extremely useful, they were not safe and reliable enough to support billions of dollars each year for increasingly powerful equipment. But the gaming industry, which recently outperformed music and movie business (together!) is profitable enough to support all needed investment for powerful hardware development to process realistic games continuous enhancement. The trick was to adapt these super modern equipment, who does millions of calculations per second, to run Machine Learning algorithms — this has only started in recent years (~ 2012), together with high forthcoming collected data volume, that explains the recent Data Science boom all over the world.
Is Data Scientist a job who only uses Machine Learning?
Short answer: No. Running Machine Learning algorithms does not turn someone in any field into a Data Scientist (and there is nothing wrong with that) — again, what defines science is methodology, not modeling. If someone is only concerned with making a prediction, for example, if there is a dog in a photo, no problem, “.fit(X, y)”, “.predict(X)” and habemus praedicere! Running a regression may or may not be science, it depends on the methodology. That is, Data Scientist uses Machine Learning, but using Machine Learning does not define a Data Scientist.

Is engineering science? What about the Machine Learning Engineer?
Of course, engineering uses a lot of science and scientific methodology, but the focus of engineering is not onto proving assumptions to be falsified or creating new models to describe society but yet solve real problems. So, while a scientist’s approach is to think skeptically about how to prove a causal effect or how to find an example that contradicts av prior theory/model, engineering is more pragmatic for knowledge application to, for example, increase process efficiency. Obviously, there is no better or worse, thus they are different concepts.


So, what is the difference in the job scope from a Data Scientist and a Machine Learning Engineer? The Scientist will be concerned with creating models that best represent reality, experimenting with hypothesis testing, and the engineer will be concerned with optimizing processes, maintaining the best possible architecture, and optimizing costs. Note that both professionals (such as DBA, data analyst, BI analyst, etc.) can/should create predictive models.

These ideas and definitions about Data Science and the Data Scientist are not yet consolidated and this text is an attempt to organize this knowledge, but it represents my idea given my experiences on the subject and like science, can still undergo through reviews, as they are confronted with reality, data and new paradigms.
Finally, a video from one of science’s greatest supporters, NASA astrobiologist Carl Sagan (1934–96), explaining what is this skeptical and humble way of thinking.